【Archive】笔记 E 星计划
E 星计划
02 渲染流程简述
GPU Driven、Mesh Cluster Rendering、Cluster whith LOD(nanite)
Mesh Shader
04 纹理综述
MRT(Multiple Render Targets)
Virtual Texture
05 光照综述
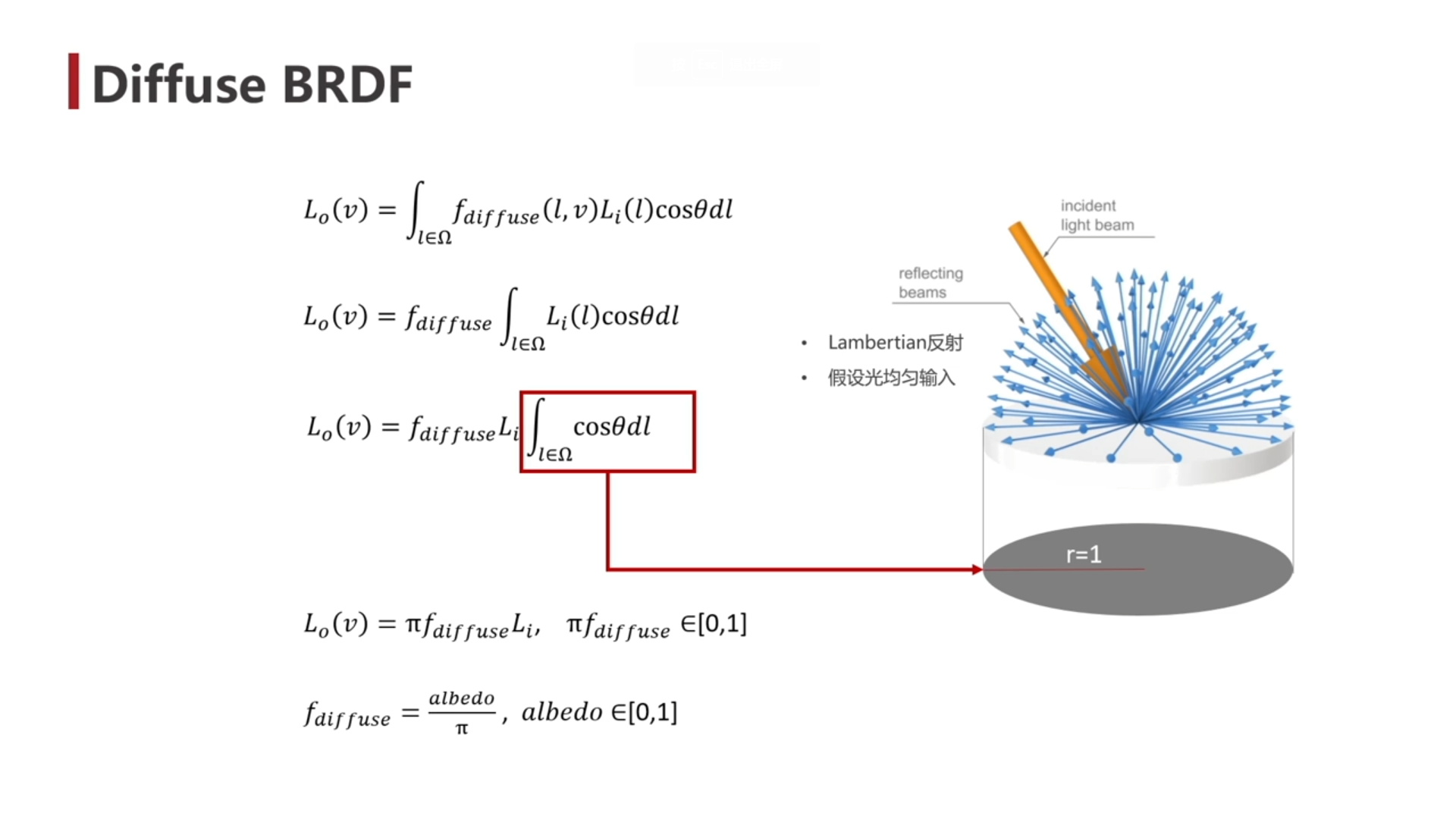
直接光漫反射
- 的范围是 ,那么 的范围是 难以理解。不如使 ,这样一来 的范围就是 了。
- 布林冯的 Diffuse Map 比较灵活,可以将一部分阴影和高光直接绘制在贴图上,但是 PBR 的 Albedo Map 只能绘制漫反射的贴图。albedo 要除以 ,看起来会比 diffuse 亮一点。

直接光高光
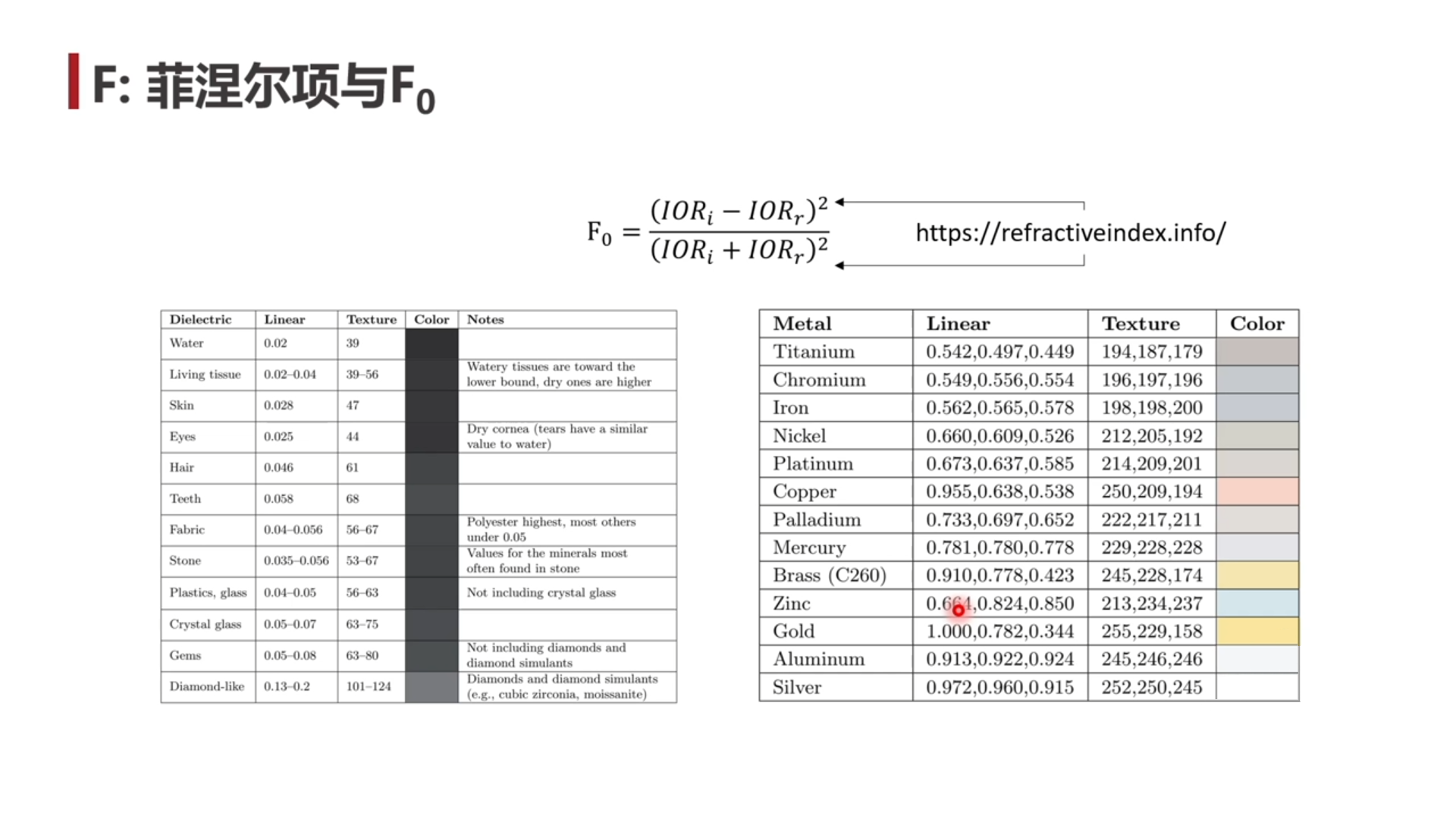
- 非金属的 F0 普遍非常小且相差无几,在实际计算中可以用一个常量(比如 0.04)代替所有非金属的材质的 F0 属性。
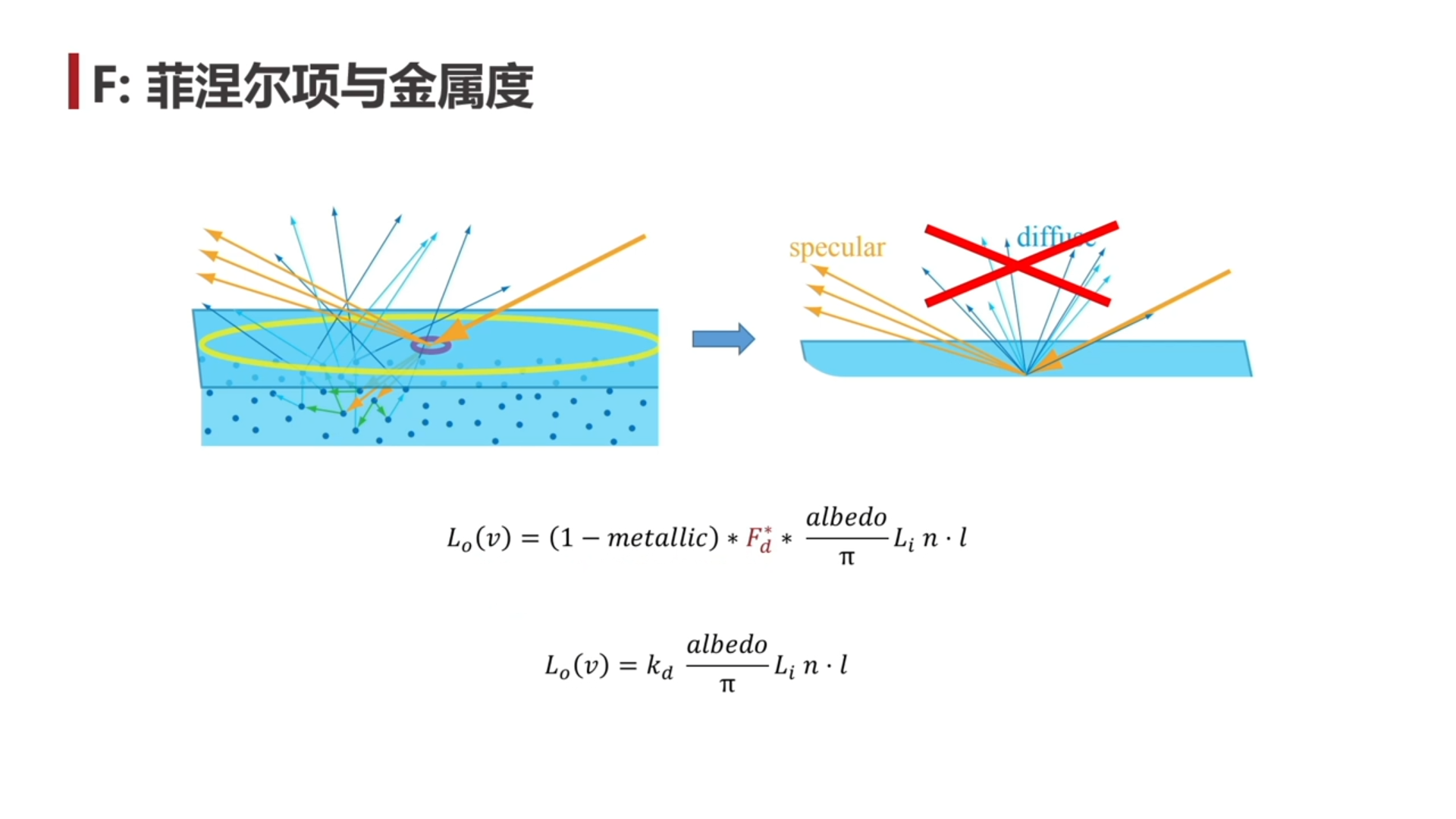
- 菲涅尔项也会影响漫反射的强度 然后 ,但是实际上不一定必须这么做。
- 金属没有 Diffuse 反射,所以 (这个 Fd 加不加都行)。
Light Culling、Clustered Shading

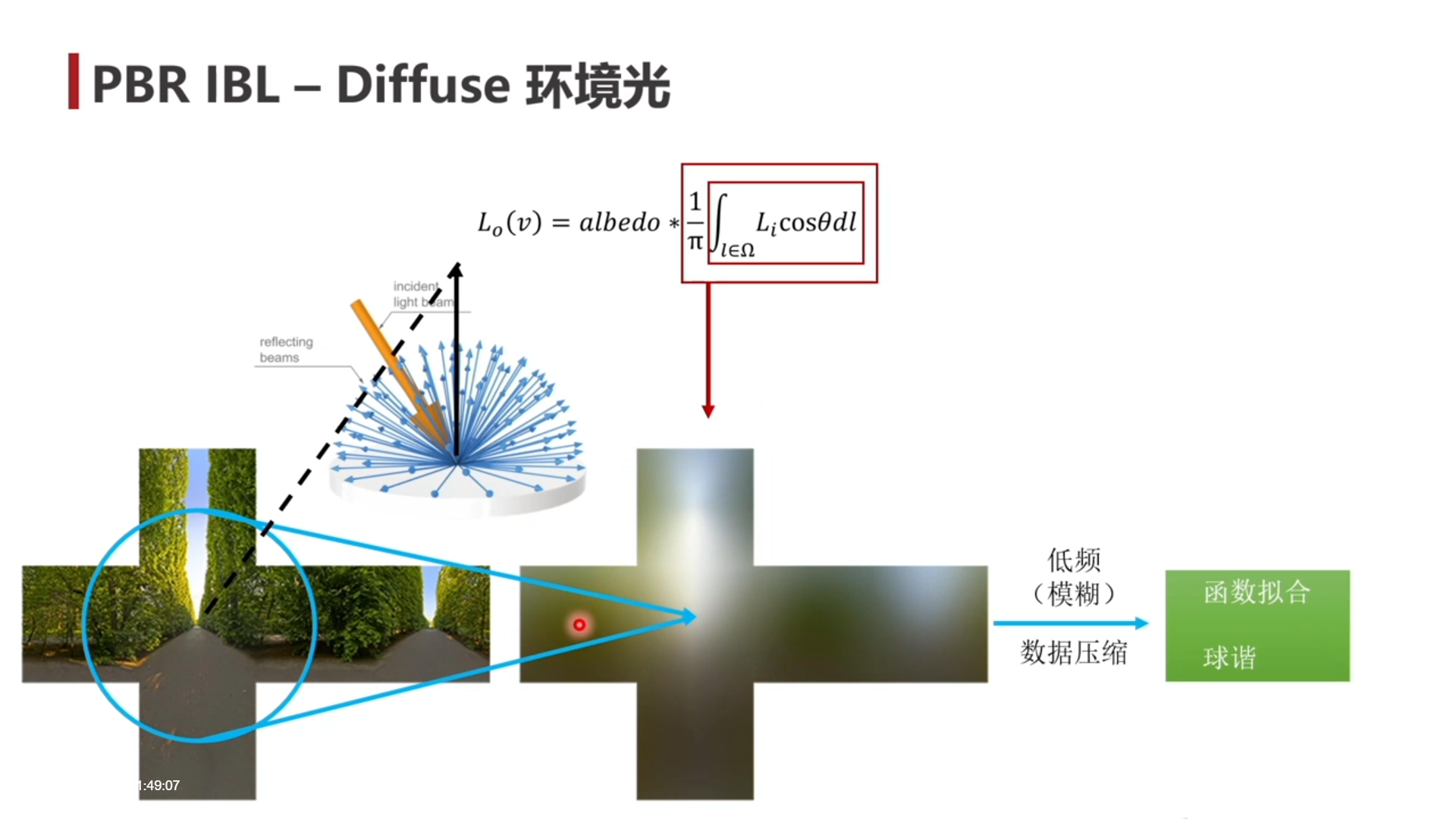
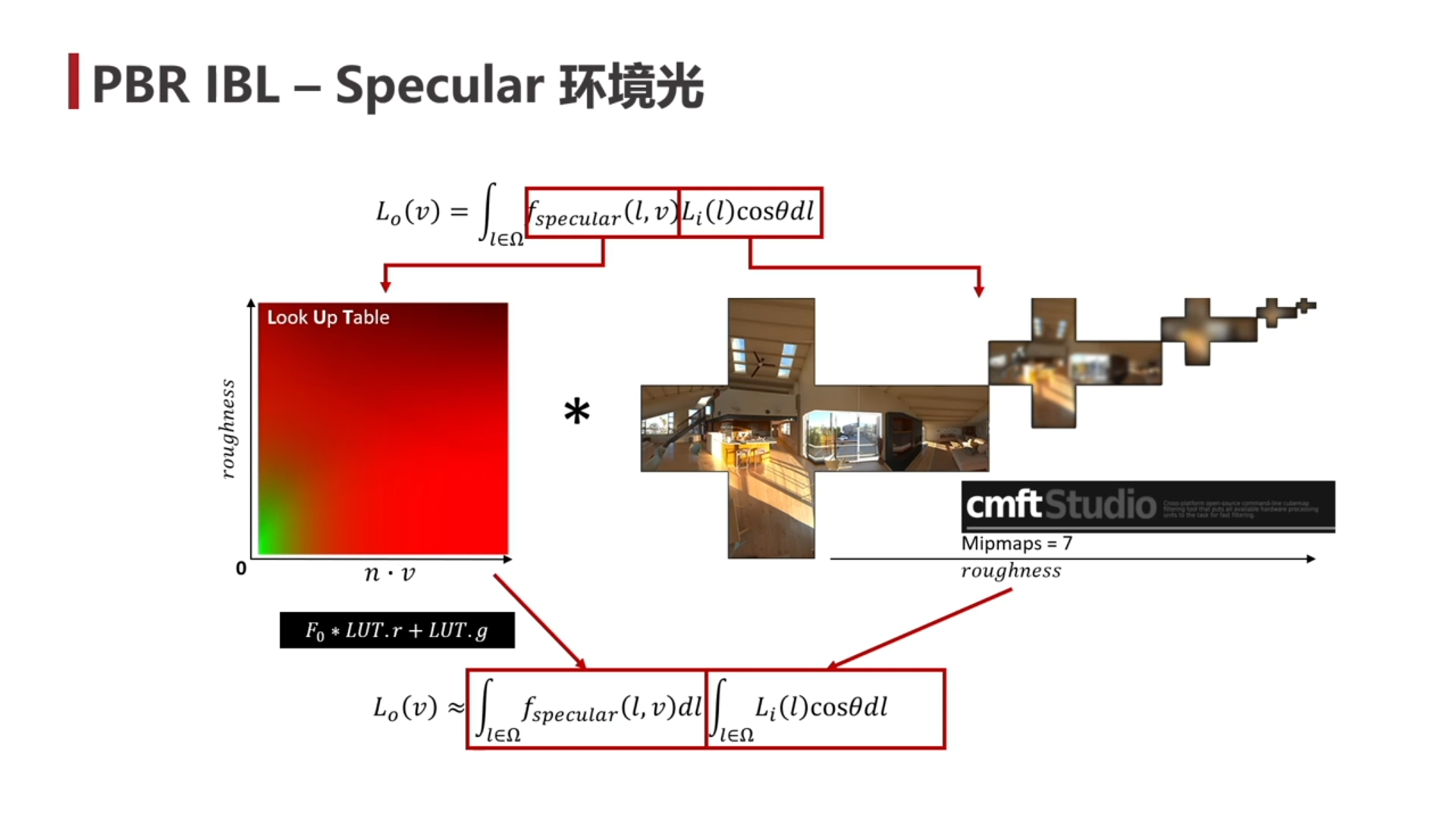
环境光
其他
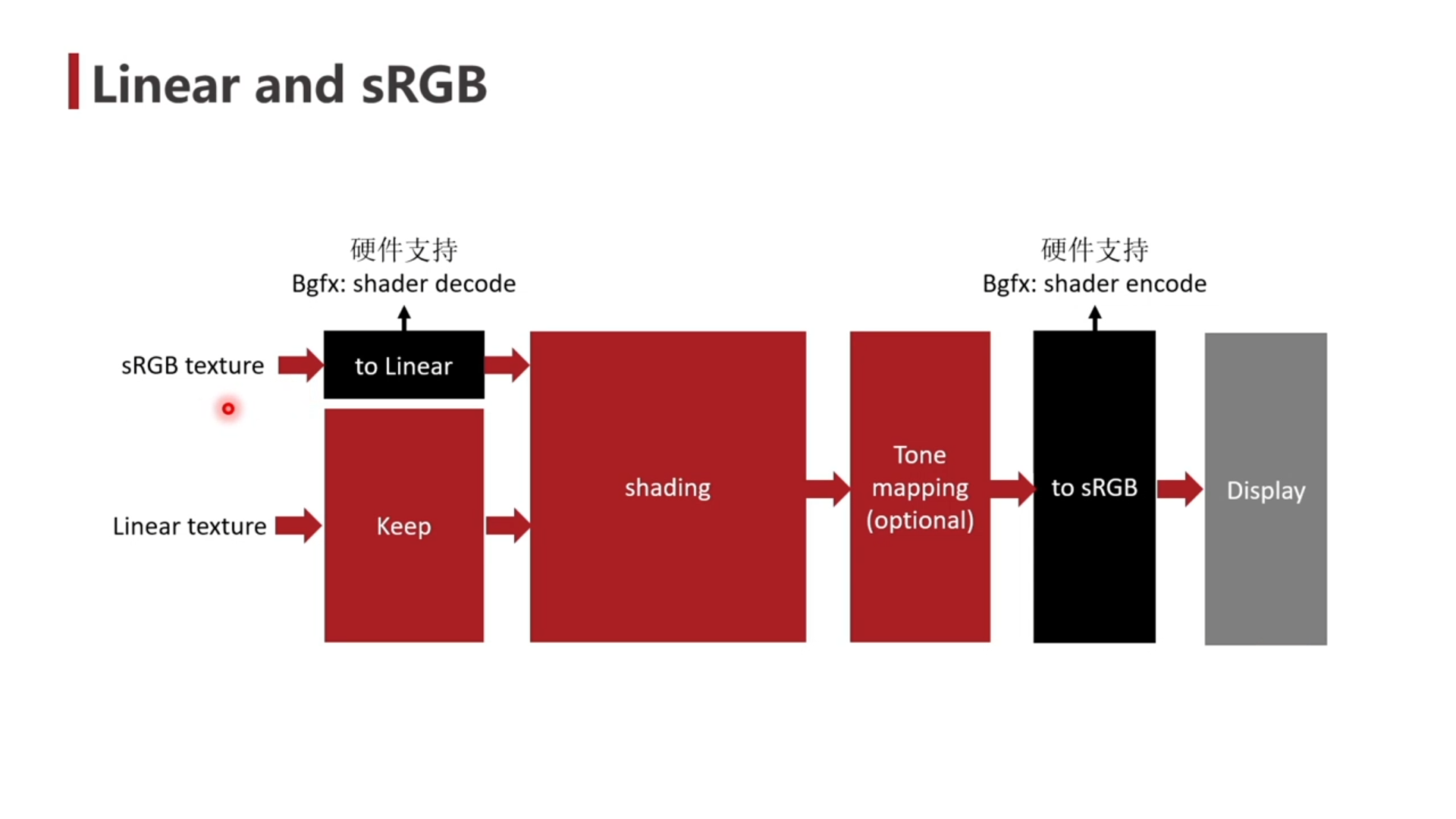
- 游戏中的 HDR 与显示器的 HDR 不是一个概念,如果显示器启用了 HDR,游戏 Tone Mapping 的曲线需要调整。
split sum approximate
06 性能优化综述
视锥剔除、遮挡剔除(硬件遮挡查询、软件遮挡查询、与计算可见集)、Triangle Cluster Culling
渲染合批
每次渲染调用涉及大量渲染状态设置和切换,显卡驱动需要根据状态组装命令队列(编码成 GPU 能理解的微指令,塞到队列里),CPU 产生开销。
骨骼动画压缩
对原始数据进行去重抽帧,拆分变换矩阵(可以进一步抽帧),对移动和缩放矩阵做线性插值,对旋转矩阵做球面插值。
用四元数表示的旋转可以用半精度的 float16 存储。
虚拟纹理
极大降低 GPU 开销:物理贴图不需要每帧更新。
消耗大量显存。
Compute Shader 可以进行运行时纹理压缩(TEC2,显卡可以直接使用,不需要解压)
可以用公式拟合一些贴图(Matlab 曲面拟合)
TBDR
过去:一个个 tile 算,算完一整张 G-Buffer 后将其存入内存,算完所有 G-Buffer 后将他们传回 GPU 进行最终的着色计算。
现在:在一个 tile 内完成全部的 G-Buffer 与着色的计算,这一小块 G-Buffer 用完即丢,不会实际进入内存。
新的 API 才支持,省显存又省带宽。
缺点是这些丢弃的 G-Buffer 在之后的流程中(比如一些后处理)无法再被访问。
07 全局光照技术综述
LightMap
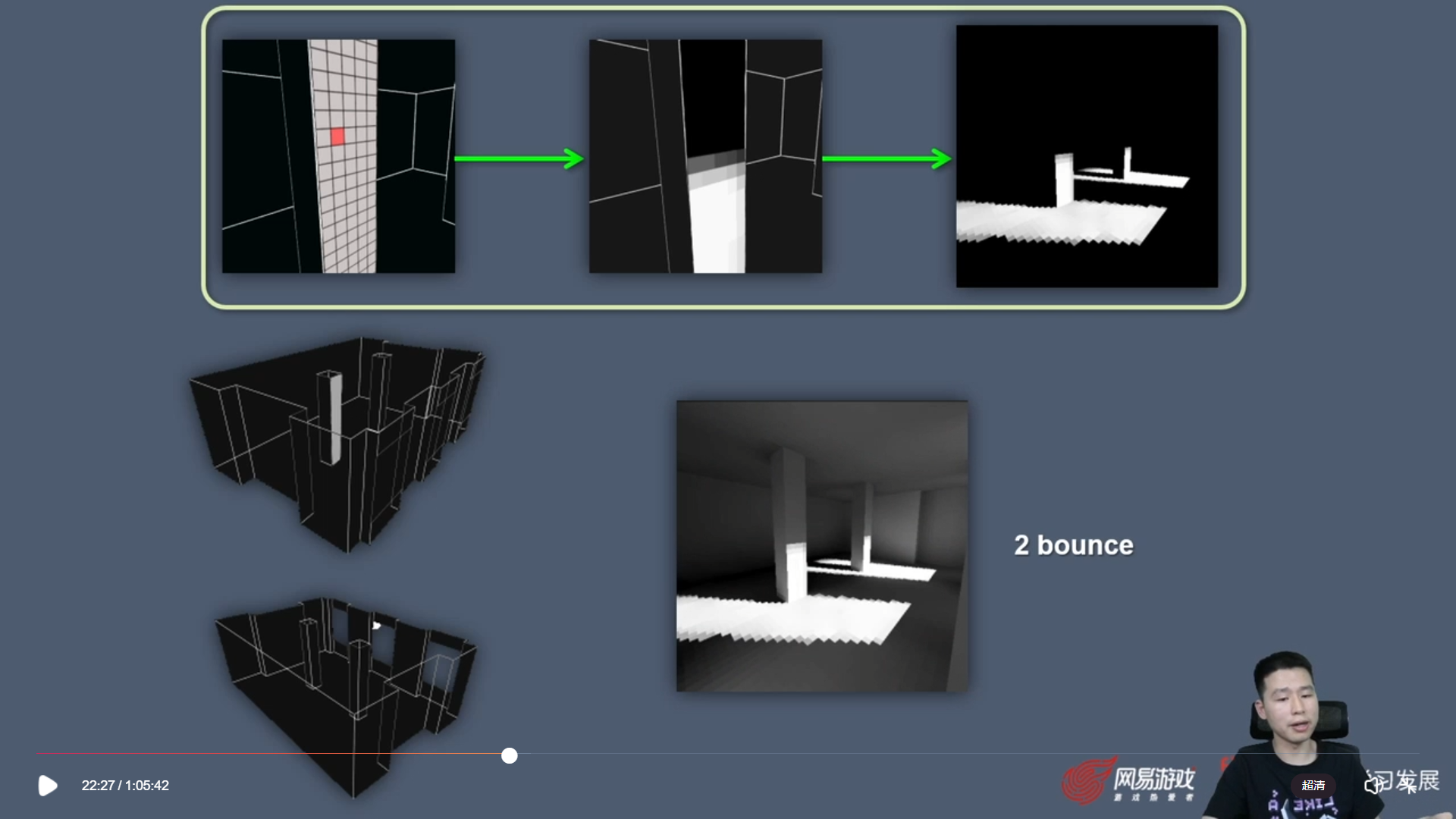
Point-Based Global Illumination
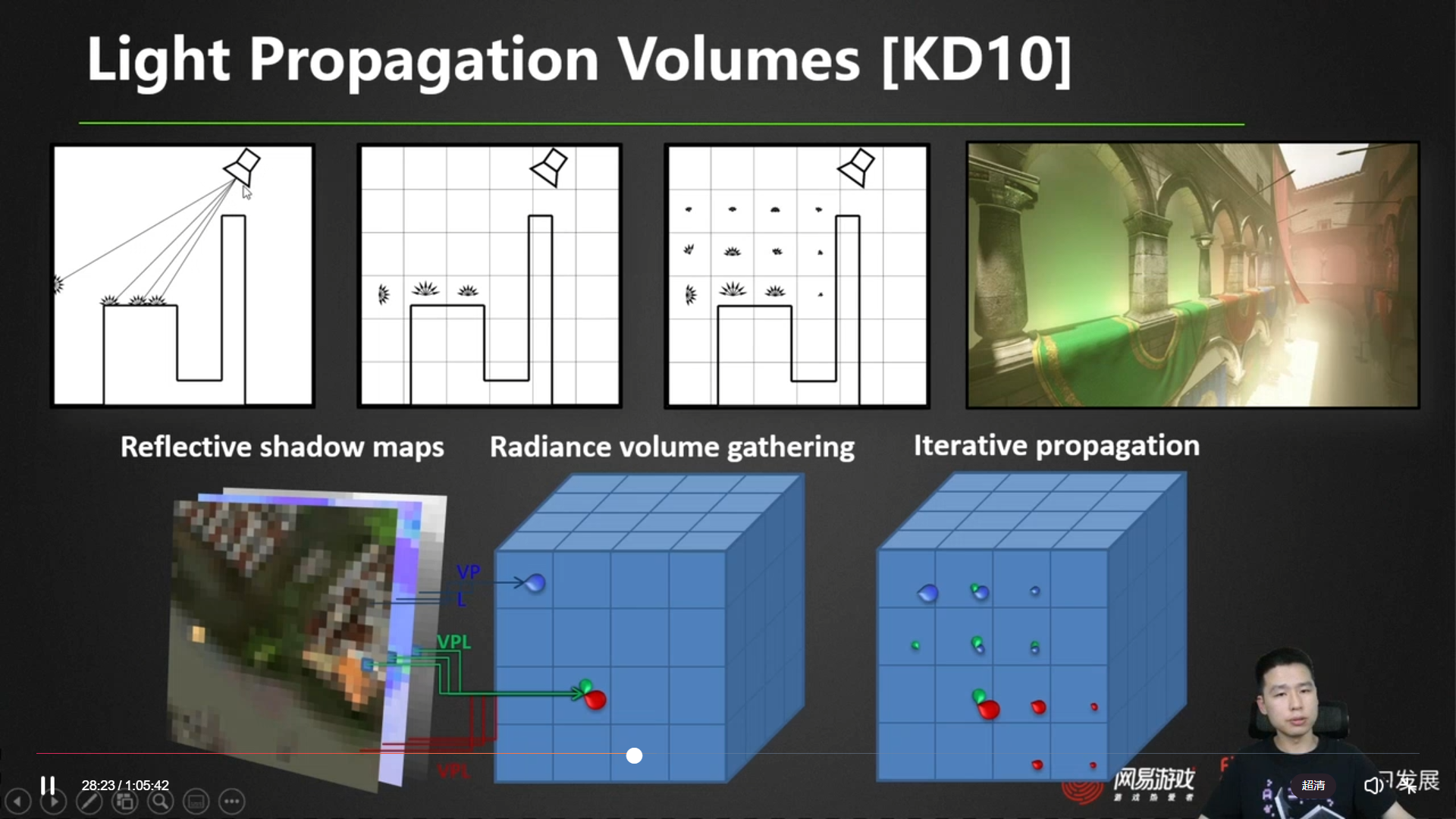
Light Propagation Volumes
SVO Cone Tracing
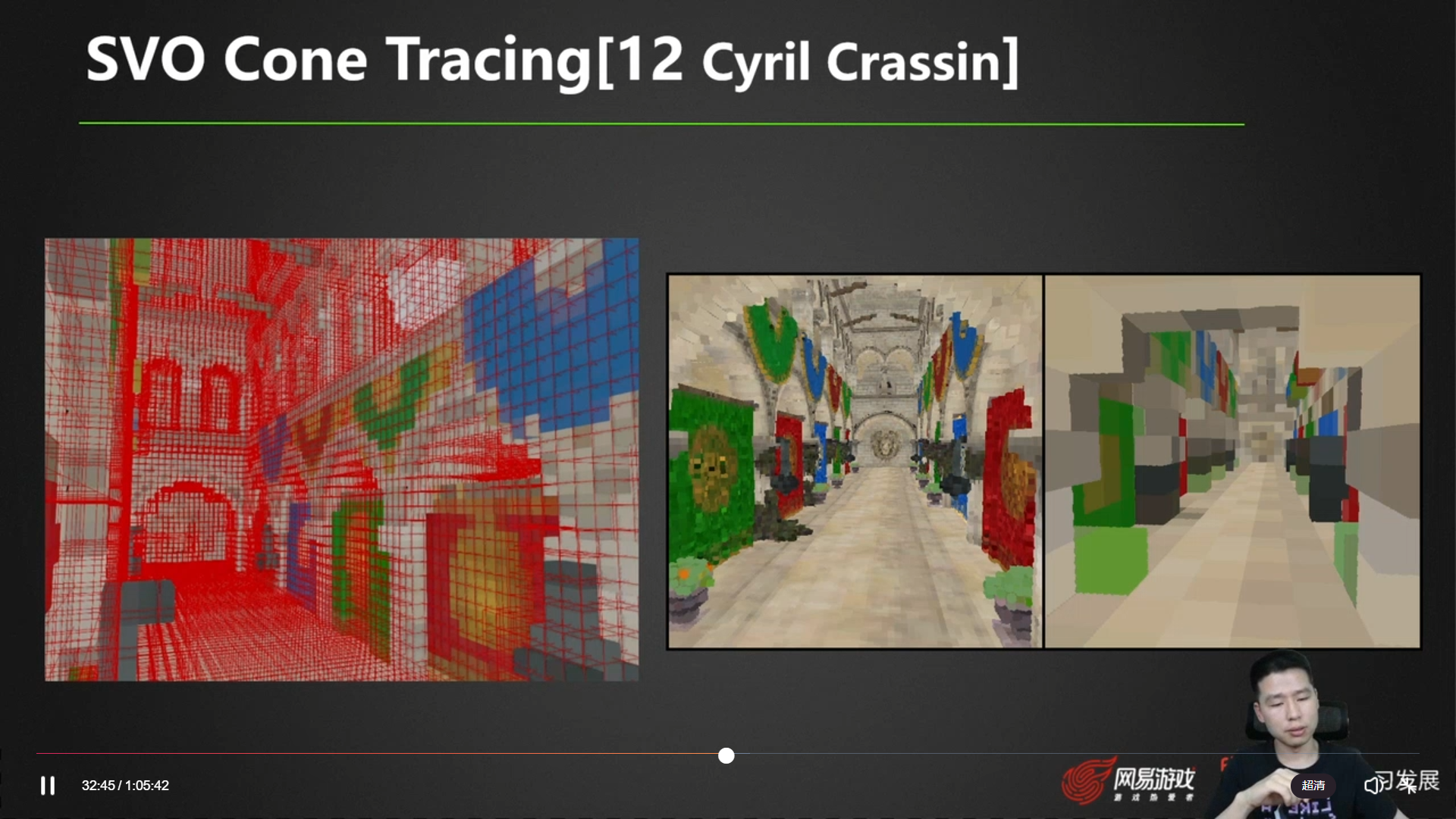
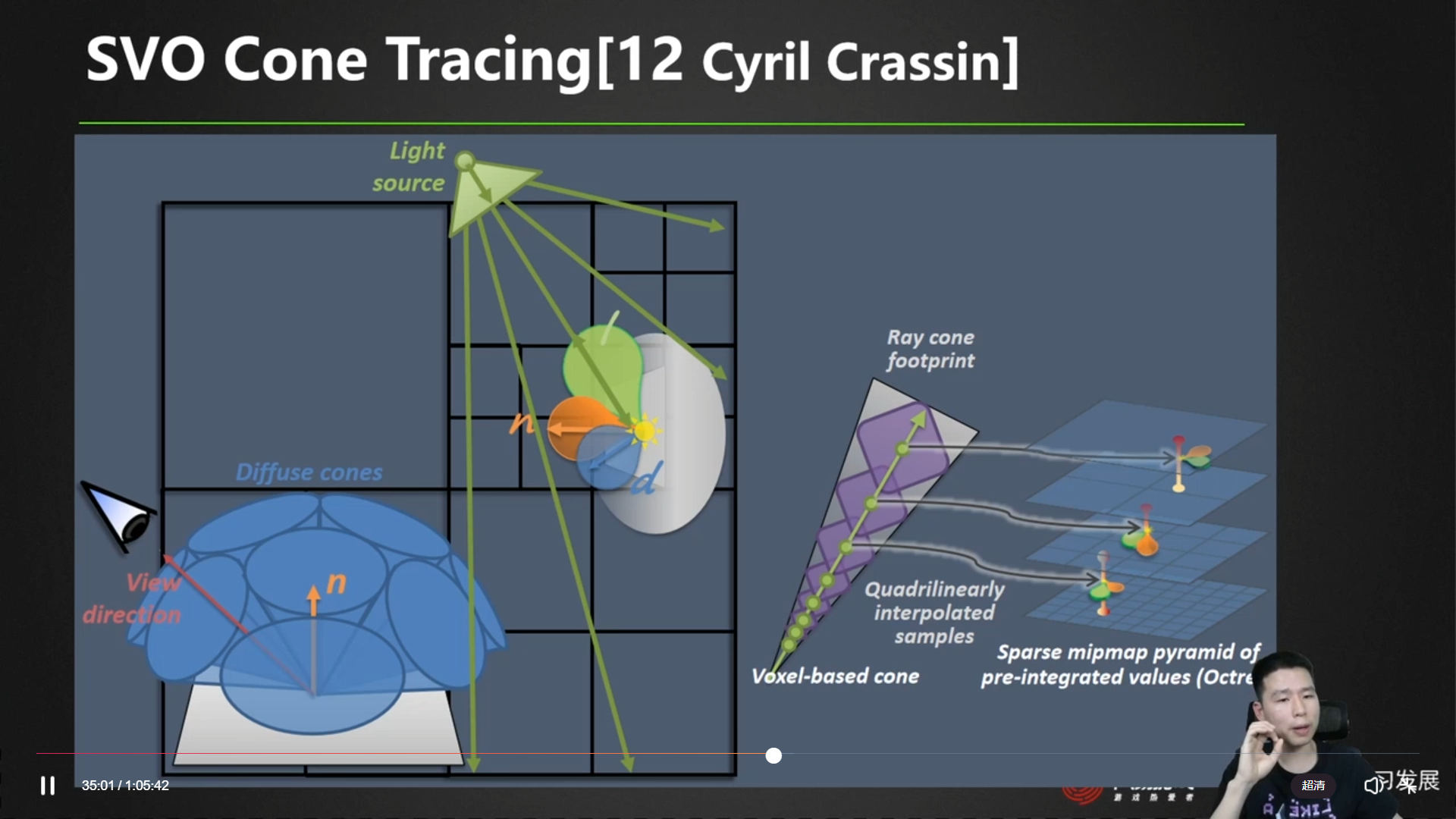
SVGF